


AWS Serverless Services - An Overview.
Top AWS Serverless Services to Learn


Serverless development booms! There is a variety of services out there that you can plug together for building your serverless application. It has a lot of benefits using them like:
- Less risk when developing
- Scalable by default
- Higher security due to encryption at rest
- On-demand costs
Of course, there are downsides as well and one of the biggest downsides is a higher complexity. This article gives you an introduction to the most important and most used AWS serverless services. I have sorted them by relevance I see in them.
All services I've added are fully managed by AWS. This should be really the focus when using serverless services to let AWS handle all of the hard work and we just take care of the business logic.
Let's go!
AWS Lambda
AWS Lambda is the serverless service. When people talk about serverless they often refer to lambda.
The basic idea behind the lambda service is to run your code without ever thinking about infrastructure. AWS’s promise is just that your code will be executed and you don't need to handle any infrastructure. Available runtimes are:
- Python
- JavaScript
- Java
- C#
- Rust
- Go
You can add external dependencies by adding them to the lambda function and interact with them like with any other program. Lambda is often used as the glue between different services. For example, streams on DynamoDB tables can trigger a lambda function to do some business logic. Or Cognito can trigger a lambda when a new user signs up in your application.
One of the latest lambda features is that custom docker containers can be used as a runtime. This makes it way easier to add dependencies as well.
Another feature was that the pricing changed from billed by every 100ms to every millisecond. Which is really awesome and resulted in a lot of reduced prices for AWS customers (there we go customer obsession 😉).
Some things to note are:
- Lambdas maximum runtime is 15 minutes! Take care of that.
- Long-running lambdas can be expensive and should be thought over.
- The most important (and only) infrastructure setting is the memory setting. You can adjust it and should test it with a framework like aws-lambda-power-tuning
AWS DynamoDB
DynamoDB is a fully-managed NoSQL database that is highly scalable and highly available. I build almost every use case and project now with DynamoDB and I am a huge fan of it. The one thing to note here is really the fully-managed approach. You do not handle anything. AWS gives you a data store and the ability to do API calls on this data. You just pay for read and write requests and a bit for the data that is stored in.
The structure of DynamoDB is pretty similar to every other document database. You have:
- Tables: A table has one or more items. For example an order table with single orders.
- Items: That is a collection of different attributes. An order could have a
customerIDand anorderIdand some other attributes. Attributes can be complex types such as maps, lists, etc. - Keys: You distinguish between partition and sort keys. An item has a primary key which can either be one ID attribute or a combination of a partition and sort key. This key identifies then the item.
- Streams: You can have streams for triggering something (e.g. a lambda function) on every update on a table. This can be very useful to build applications in an event-driven architecture.
DynamoDB is basically a key, value database where you can store different data types as a value. A value can also be a nested list or nested list of objects (like JSON). A DynamoDB Item looks like that:
{
"ISIN":{
"S":"DE0005190003"
},
"name":{
"S":"BAY.MOTOREN WERKE AG ST"
}
}
The key is the column name (in this case ISIN -> Identifier for a stock and the value is another object with the key as the data type (S -> String) and the value with the actual value. Many frameworks or SDKs (like the document client) can display it in a normal JSON syntax:
{
"ISIN": "DE0005190003",
"name": "BAY.MOTOREN WERKE AG ST"
}
DynamoDB has some great features for increasing the performance even more such as Global Tables, DynamoDB Accelerator, Point-In-Time recovery, and many more. When designing DynamoDB tables it is always important to keep your access patterns in mind. Rick is doing a wonderful job explaining DynamoDB strategies in this video.
In general Single-Table design is really great and I can highly recommend Alex's blog for more information on that. When designing DynamoDB models I would always think about using DynamoDB with either one table and Single-Table Design or in combination with AppSync, GraphQL, and several tables.
AWS AppSync
AWS AppSync is a fully-managed GraphQL API. The same thing as with DynamoDB, fully-managed here is the key. AWS gives you the opportunity of using a GraphQL API without managing any infrastructure!
GraphQL in general is great and finds more and more adoption. Basically, the developer who uses a GraphQL API can define exactly the data he needs without worrying about fetching different APIs and getting too much or too little data (no over-etching or under-fetching). With GraphQL you always have three different operations, that are:
- Queries
- Mutations
- Subscriptions
In AppSync you create a data schema with types and attributes. A common example is a to-do app:
type Query {
getTodos: [Todo]
}
type Todo {
id: ID!
name: String
description: String
priority: Int
}
This schema would create a type ToDo with some attributes and a query to query this data named getTodos. Each field is associated with a so-called resolver. This brings great flexibility to AppSync. Some fields can be stored in a DynamoDB table and some other fields can be stored in another data store or be queried by a lambda function that requests an external API. Especially in combination with pipeline resolvers and AWS Lambda, it is extremely powerful to use AppSync.
There are many more things you can do with the schema but the great thing is that your API is typed and everyone knows exactly which data is available and it is easily possible to query through different data types with just one query (that is why it is called a Graph). See more information on the schema here.
If you use AppSync in combination with Amplify CLI they even offer you more capabilities and let you provision cloud infrastructure and create resolvers for you automatically by annotating the schema with some directives. All of these can be seen in the graphql-transform documentation.
Amazon API Gateway
Amazon API Gateway is the equivalent to AppSync just for REST APIs. The great thing here again is that it is fully managed. You just define your paths, inputs, outputs and the infrastructure is fully handled by AWS. With API Gateway you can either create RESTful APIs or WebSocket APIs. It integrates with a lot of different services in the whole AWS ecosystem of course, such as:
- AWS Lambda
- Amazon Kinesis
- Amazon DynamoDB
- Amazon EC2
- Amazon CloudWatch
Amplify
The next service I introduce is Amplify. Amplify refers to a lot of different things and I go more into detail here. Now I am just referring to the two services:
- Hosting
- Console aka CI/CD
Hosting
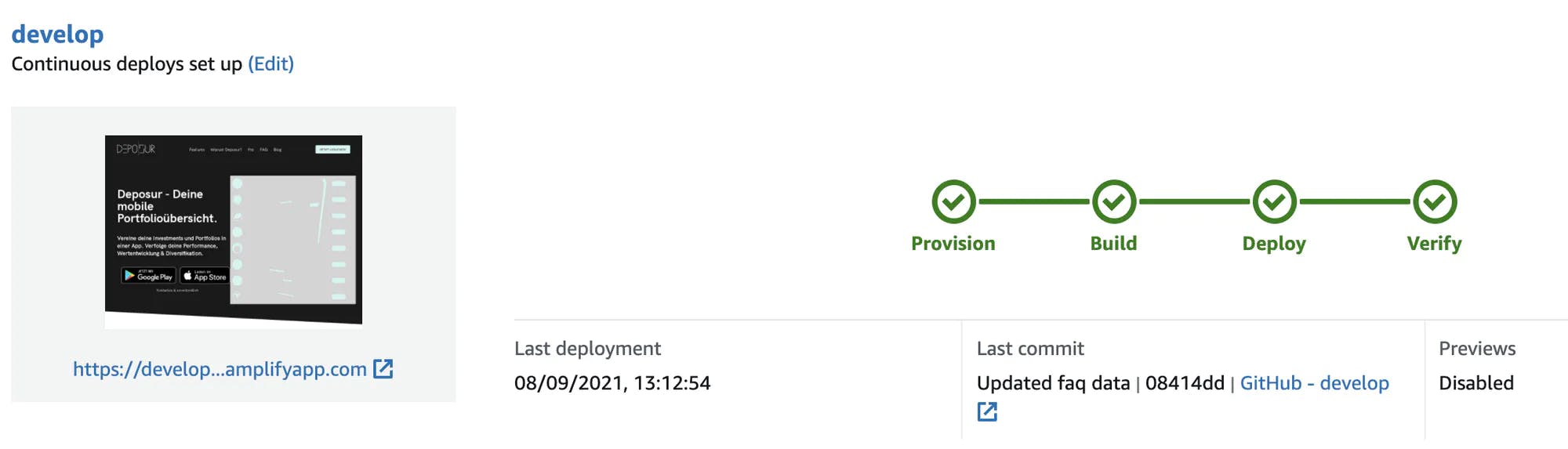
Hosting is there for you if you want to host your static web page. For example, you have a React application and want to host it, Amplify Hosting is there for you. You can simply connect your Git branch, let it trigger a build on the master branch and it will be deployed on a reserved domain by Amplify. You can also add your custom domain.
Some of the main features are:
PR Preview:
Amplify Hosting allows you to preview new PRs in a completely own environment to test out new features
Custom and not custom domains:
Amplify Hosting published your web page normally on some Amplify domain such as develop.d23z478fg.amplifyapp.com. This is done automatically. If you want to map custom domains you can easily do this.
SSL Certificate included:
SSL is automatically included in both custom and not custom domains.
Monitoring:
You can monitor the metrics of the application and get SNS notifications in case you reach certain thresholds. Under the hood Amplify Hosting uses S3 and CloudFront to deliver your webpage over the globe. It abstracts the hassle of setting everything up manually and gives you a lot of options to customize the experience.
Console
Amplify Console is the CI/CD component of Amplify. It allows you to build full-stack apps by building your backend, frontend and deploying all of it with Amplify Hosting.
The console follows a git-based workflow. That means it will automatically be triggered by pushes or PRs on your git branches. The console build is based on a docker image which you can adjust to anything you want. After setting the image you can define your build in the build.yml file and follow several phases. The phases are:
- Provision: All AWS resources for the build will be provisioned
- Build: Backend and frontend deployment
- Deploy: Everything will be deployed.
- Verify: Tests will be executed
Amazon S3
Amazon S3 is the object storage and BLOB storage of AWS. It is one of the oldest services (not the oldest though!) in the whole AWS ecosystem. It gives you the ability to ingest a huge amount of data, storing this data with a lot of different options and analyzing it with different services. S3 has one of the best availability numbers out there with 11 9s!
Amazon Cognito
Amazon Cognito is an Authentication service. With Cognito, you can build authorization and authorization concepts into your app. Cognito also offers you to use federated login via Facebook, Google & Apple which makes it way more seamless to log in for your users.
In Cognito you differentiate in User Pools and Identity Pools:
User Pools: Directory of users with Sign-Up, Sign-In, and federated login capability.
Identity Pools: Identity pools are for creating unique identities for users and giving them access to other AWS services. This is needed for example for generating temporary credentials for anonymous users.
The typical workflow will use User Pools.
A wise man said you don't build authentication by yourself. That means using an external service. Cognito is exactly that service!
AWS Step Functions
AWS Step Functions allows you to glue a lot of services together. It had one the biggest updates in September by adding support for more than 200 AWS services.
AWS Step Functions gives you the ability to create your services in a visual way.
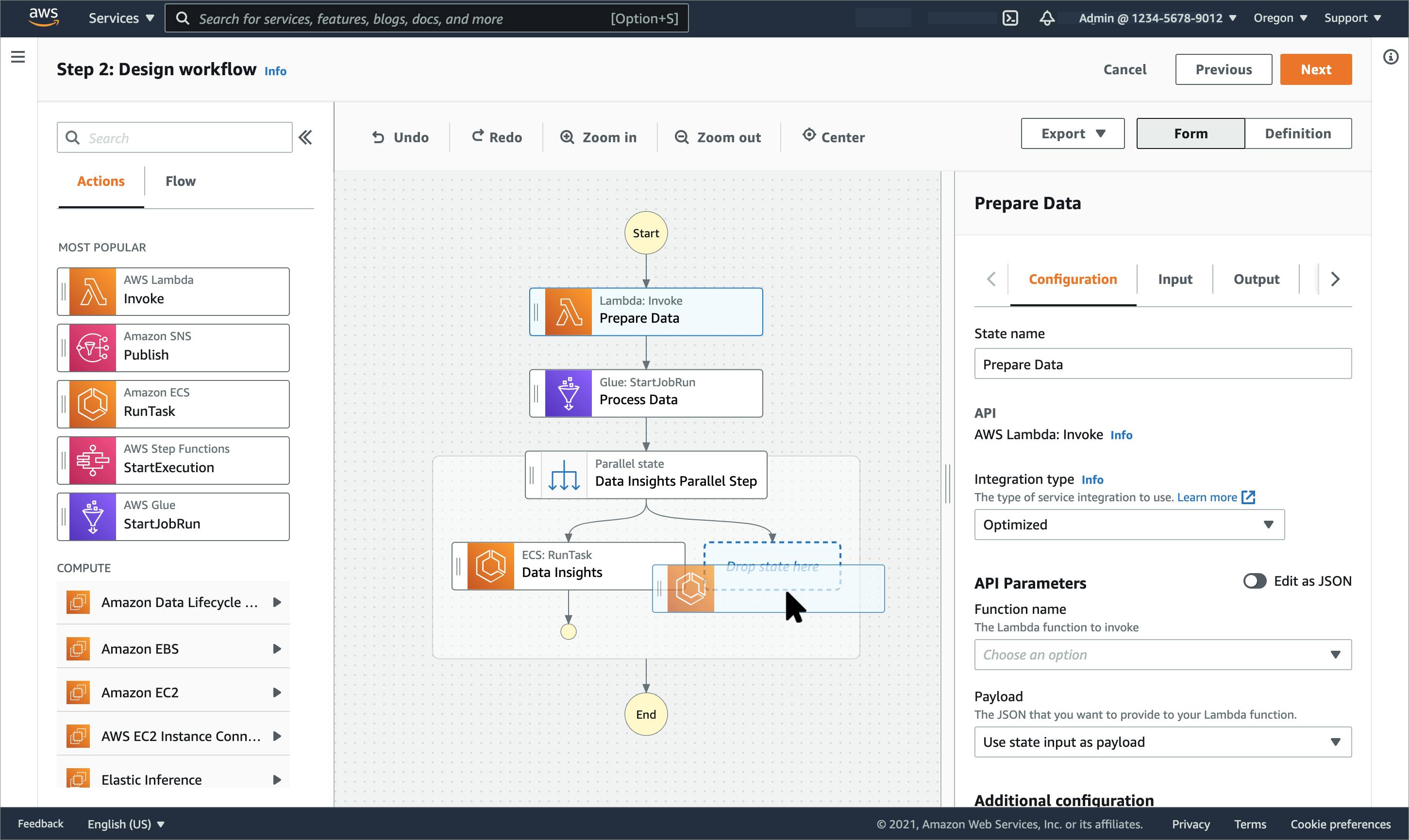
With the workflow studio it is easily possible to connect different services together and have a look at the data flow. It should change the data flow by using fewer lambda functions and more communication between the services directly.
AWS SQS
AWS SQS is the Simple Queue Service.
Fun Fact: SQS is the oldest AWS service!
SQS allows you to send messages from one source to another one. A common example can be:
- Lambda 1 queries data from DynamoDB
- Lambda 1 sends messages to SQS
- SQS triggers Lambda 2 with just one or two messages
While using SQS please have in mind that AWS executes almost everything at-lest once. That means your messages can arrive twice. You need to implement your things in an idempotent way.
SQS offers you two types of queues:
Standard queues
The standard queue is a simple queue that executes your messages at least once and triggers another service. The order in which the messages are executed is not guaranteed.
FIFO queue
The FIFO queue guarantees the order of the messages and executes the message exactly-once. The FIFO queue is doing this because you need to enter a DedpulicationID in the message. FIFO is a bit more expensive.
Final words
That's it! I hope you could gain an overview of all the different services out there. I excluded things like Fargate and Aurora Serverless on purpose because they are both not paid on demand are IMO not completely serverless but still great services.
If you want to see how I use these services to build digital products follow me on Twitter