


How to develop a serverless mobile app with Amplify, React Native & GraphQL
Build apps that scale.


This post will show you an introduction to the architecture of a cross-platform (Android & iOS) mobile application. The app was built with React Native, Amplify, and GraphQL. I'll take my own application deopsur as an example and explain all services and components based on this application. Deposur is an app for tracking your portfolios and investments.
Let's first talk about why serverless and cross-platform.
Why Serverless?
First of all, let's talk about why to develop an application serverless. These are the main reasons:
I could go on with potential benefits such as development time, costs, etc. but I think many of you know these benefits already.
Why cross-platform.
Cross-Platform development means that you render two native apps from just one codebase. This brings the main benefit that you just have to maintain and test this codebase. Of course, sometimes there are situations where you have to distinguish between both, for example in terms of styling, but this can be easily done.
The Architecture
Let's go over the architecture. I will explain the technologies, services, and components I used and why I used them. I separate the architecture into frontend and backend.
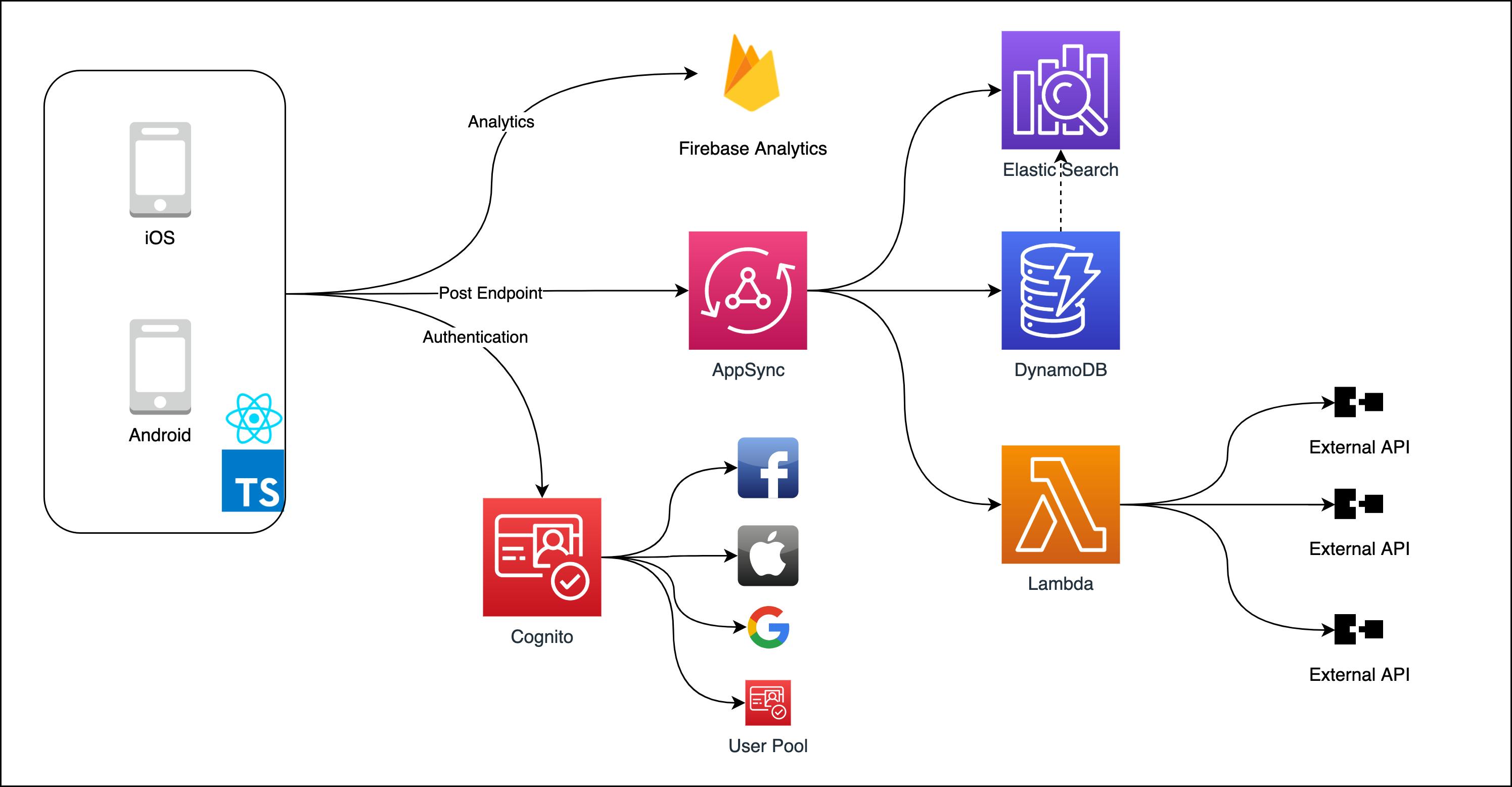
Frontend
The frontend tech-stack has the following components and technologies:
- React Native
- TypeScript
- react-native-elements
- Apollo (GraphQL)
React Native
React Native is an open-source framework, originally developed by Facebook for creating cross-platform applications with JavaScript. The main difference to other cross-platform technologies such as Cordova or Ionic is that the apps will not just be rendered in a web browser, but instead will be a proper native application. To have the same experience as with native applications, some customization for both platforms has to happen.
TypeScript
React Native and its libraries are almost all supported in TypeScript. TypeScript is an additional layer to JavaScript built by Microsoft to have type-safety in your JavaScript code. The number one reason for using TypeScript is developer experience. This reason is often overlooked but it is so important to know which types you're passing around in your code. Especially, in the combination with GraphQL, it is really awesome to know which kind of data you will receive with which requests.
react-native-elements
react-native-elements is an UI component library. It offers you customizable assets which you can reuse throughout your app. It implements the Material Design that is really popular in Google applications. There are many component libraries out there, we built the first version of Deposur with UI Kitten but quickly switched back to react-native-elements for the theming and component implementation.
Apollo
For managing the internal state of the app we use Apollo in combination with AppSync and GraphQL. Apollo caches all queries and normalizes them by a key schema we define at the initialization of our app. It reduces the boilerplate and the complexity of using state management libraries such as Redux. It has some awesome capabilities like defining how to cache the data (network, local, etc.), when and how to refetch queries, and updating local data for optimistic mutations.
Backend
Since this article is talking about building a serverless app, let's dive into the backend part. The main idea you want to focus on when building severless is to not managing any infrastructure by yourself. Use as many managed services as possible and just take care of your business logic. The following parts will be separated into the different AWS services I'll recommend for building this kind of application.
Amplify
Amplify can be distinguished into three different services:
- Amplify-CLI: Infrastructure as code and graphql-transform
- Amplify-Console: CI/CD pipeline
- Amplify libraries: Frontend libraries for accessing AWS services.
I recommend using all three but this section is focused on the CLI.
Infrastructure as Code
Amplify-CLI gives you the opportunity to bootstrap your cloud environment with a few CLI commands and it creates CloudFormation templates for you automatically. This is also called Infrastructure as Code (IaC).
For example, if you type in:
> amplify add storage
? Please select from one of the below mentioned services:
> Content (Images, audio, video, etc.)
NoSQL Database
? Please provide a friendly name for your resource that will be used to label this category in the project:
> dynamodb
? Please provide table name:
> tablename
Amplify creates several CloudFormation templates for the database, IAM permissions, etc.
GraphQL Transform
The main benefit of using Amplify is the graphql-transform library. It gives you the opportunity to annotate your graphql.schema with annotations such as model, connection, searchable, or auth for adding certain functionality and components to your architecture.
Take for example this schema:
type Holding
@model
@searchable
{
id: ID!
ISIN: String!
currentPrice: Float! @funtion(name: priceResolver)
}
The model directive adds a DynamoDB table of the type Holding to your backend. Also, it adds an ElasticSearch Service and streams all data to this instance. The field currentPrice will be resolved by a lambda function called priceResolver.
Deployment
Amplify also takes care of the deployment of all CloudFormation templates. This can be sometimes a headache (hello nested stacks) but in general, it takes away a huge burden. It also manages the deployment to different stages such as development, staging, and production.
If you start building your serverless app I highly recommend checking out Amplify because it is an awesome project, has a great community, and gives you some really cool tools at hand for building your full-stack application. Be aware that some magic is happening in the background.
AppSync
AppSync is the managed GraphQL API by AWS. It is one of the most unique services AWS offers in the serverless area. AppSync allows you to use almost any data source you want and map it to certain types. First of all, you need to define your GraphQL schema. We take the same one we saw before.
type Holding
@model
@searchable
{
id: ID!
ISIN: String!
currentPrice: Float! @funtion(name: priceResolver)
}
Note: This is not a valid AppSync schema but a valid Amplify GraphQL schema.
Since we are using Amplify in combination with AppSync we can use these directives. We already mentioned that the field currentPrice will be resolved by a lambda function. In general AppSync fields can be resolved by one of these two methods:
- VTL Templates: Velocity Templating Language. This is a templating language developed by Apache which is not completely straight forwards.
- Lambda Resolvers: You can use lambda functions for returning your fields.
Amplify automatically generates VTL templates for your DynamoDB fields, for lambda resolvers you have to add the lambda function to your project and return the attributes you defined.
Query, Mutations, and Subscriptions
This is not a complete GraphQL introduction. But in general, you can either query, mutate or subscribe your data. A query looks like that:
query MyQuery {
getHolding(ISIN: "DE0005190003") {
ISIN
currentPrice
}
}
`
And it returns a JSON object:
{
"data": {
"getHolding": {
"ISIN": "DE0005190003",
"currentPrice": 90.94999694824219,
}
}
}
A mutation looks similar, just that you often have an input object which you have to pass.
Benefits
We only use AppSync and GraphQL in our API for all data. There are two main benefits involved:
- Frontend gets the power
The frontend gets the power of fetching exactly the data it needs. There is no over-, or underfetching in GraphQL. You just get the data you specify to get.
- State management
With GraphQL & Apollo, it is fairly easy to manage your state and cache in your app. You begin by normalizing your keys for the types in your schema and have them in your in-memory-cache.
Lambda
Lambda is the most known serverless service of AWS. As already mentioned in AppSync, lambda is purely used for our business logic as AppSync resolvers. Lambda executes your code without ever thinking about hardware. The main configuration is the memory setting which should always be maximized a bit to ensure fast execution.
We follow the approach of having one lambda function as a resolver for all AppSync fields and Lambda layers for handling the dependencies.
The Lambda resolver is responsible for the following things:
- Getting the live price from a third-party API
- Getting historical prices from a third-party API
- Doing aggregations of the data
- Calculate different indicators such as the average buy-in price, invested capital, etc.
This is the main use case of using Lambda here. There are also some minor use cases such as payment webhooks, newsletter campaigns, and monitoring services but the resolver is our main business logic.
DynamoDB
DynamoDB is an amazing service. It is a fully managed NoSQL database by AWS. In combination with GraphQL, Amplify, and AppSync it works really well. Basically, it is a key-value database with JSON-like objects.
All our DynamoDB tables come directly from our GraphQL schema. Amplify creates them automatically. We mainly access DynamoDB via VTL resolver from AppSync or our Lambda resolver for aggregating and mutating data.
ElasticSearch
The last data source we use is the full-text search engine elastic search. It integrates really smoothly with using Amplify and all data gets streamed into elastic search automatically. You can query your data and execute searches with GraphQL as well. AppSync maps them via VTL resolvers. You can use different search operators such as eq, ne, matchPhrase, and many more.
It is really powerful, but unfortunately also the most expensive piece in this architecture. Since elastic search is not serverless it is an instance that runs 24/7. Take this into consideration and think about it to use it or not! If you don't have a complex search use case try to use smart access patterns within your DynamoDB and use them as an initial search.
Cognito
Cognito is the authentication service in AWS. I (and many others) would always recommend never building certain systems by yourself. One of them is an authentication system. Arvid Kahl proves my point here as well:
Cognito takes this burden away. It offers a sign-in and sign-up functionality even with a pre-defined hosted UI for signing up which you can integrate with no effort.
The main benefit is to use social-sign-in functionality within your app. By using these features you give your users the opportunity to log in seamlessly with just one click.
Cognito supports the following social sign-in provider:
- Apple
- Amazon
Also, all functionalities like changing your password, resetting your password, etc. are supported natively by Cognito and you don't have to build it yourself.
Firebase Analytics
The last service I show you is not from AWS but from GCP. Indeed, I thought about this a lot, but Firebase Analytics is just working way better and nicer compared to AWS pinpoint. Not just the UI is nicer (that is almost always the case if you compare GCP to AWS) but also the functionality is way better to incorporate into your mobile app. I recommend using react-native-firebase for integrating Firebase into your app.
Costs
One word about costs. Using this architecture as your app backend with an initial low number of users will cost you about nothing if you do not use elastic search.
If you use the smallest elastic search instance it will cost you about 20€/instance/month.
All other components will be completely in the free tier and just be billed on demand. That means if you really just have a low number of users it won't cost you anything. This reduces the risk immensely. If it starts to cost you money, or if you need a full-text search you can always apply for the activate program and get 1000$ in credits for free.
Conclusion
In this article, I showed you how an example serverless architecture for a cross-platform mobile application looks like. By learning this architecture you can apply it for so many different use cases. You are of course not restricted to mobile apps only, instead you can use it for all full-stack applications.
Of course, we somehow cheat by using Amplify here but this really helps with building up your infrastructure in a fast and secure way.
If you want to see more on building & bootstrapping serverless applications, follow my Twitter 🙂
Thanks!